Person Re-Identification by Video Ranking TPAMI'16, ECCV'14
Introduction
Current person re-identification (re-id) methods typically rely on single-frame imagery features, and ignore space-time information from image sequences. Single-frame (single-shot) visual appearance matching is inherently limited for person re-id in public spaces due to visual ambiguity arising from non-overlapping camera views where viewpoint and lighting changes can cause significant appearance variation. In this work, we present a novel model to automatically select the most discriminative video fragments from noisy image sequences of people where more reliable space-time features can be extracted, whilst simultaneously to learn a video ranking function for person re-id. Also, we introduce a new image sequence re-id dataset (iLIDS-VID) based on the i-LIDS MCT benchmark data. Using the iLIDS-VID and PRID 2011 sequence re-id datasets, we extensively conducted comparative evaluations to demonstrate the advantages of the proposed model over contemporary gait recognition, holistic image sequence matching and state-of-the-art single-shot/multi-shot based re-id methods.
Contribution Highlights
- We derive a multi-fragments based space-time feature representation of image sequences of people. This representation is based on a combination of HOG3D features and optic ow energy profile over each image sequence, designed to break down automatically unregulated video clips of people into multiple fragments.
- We propose a discriminative video ranking model for cross-view re-identification by simultaneously selecting and matching more reliable space-time features from video fragments. The model is formulated using a multi-instance ranking strategy for learning from pairs of image sequences over non-overlapping camera views. This method can significantly relax the strict assumptions required by gait recognition techniques.
- We introduce a new image sequence based person re-identification dataset called iLIDS-VID, extracted from the i-LIDS Multiple-Camera Tracking Scenario (MCTS). To our knowledge, this is the largest image sequence based re-identification dataset that is publically available.
Citation
-
Person Re-Identification by Video Ranking.
T. Wang, S. Gong, X. Zhu, and S. Wang.
In Proc. European Conference on Computer Vision, Zurich, Switzerland, September 2014.
[PDF] [CMC] [Data Splits] [Spotlight Video] -
Person Re-Identification by Discriminative Selection in Video Ranking.
T. Wang, S. Gong, X. Zhu, and S. Wang.
IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 38, No. 12, pp. 2501-2514, December 2016.
[PDF] [arXiv] [CMC]
Images
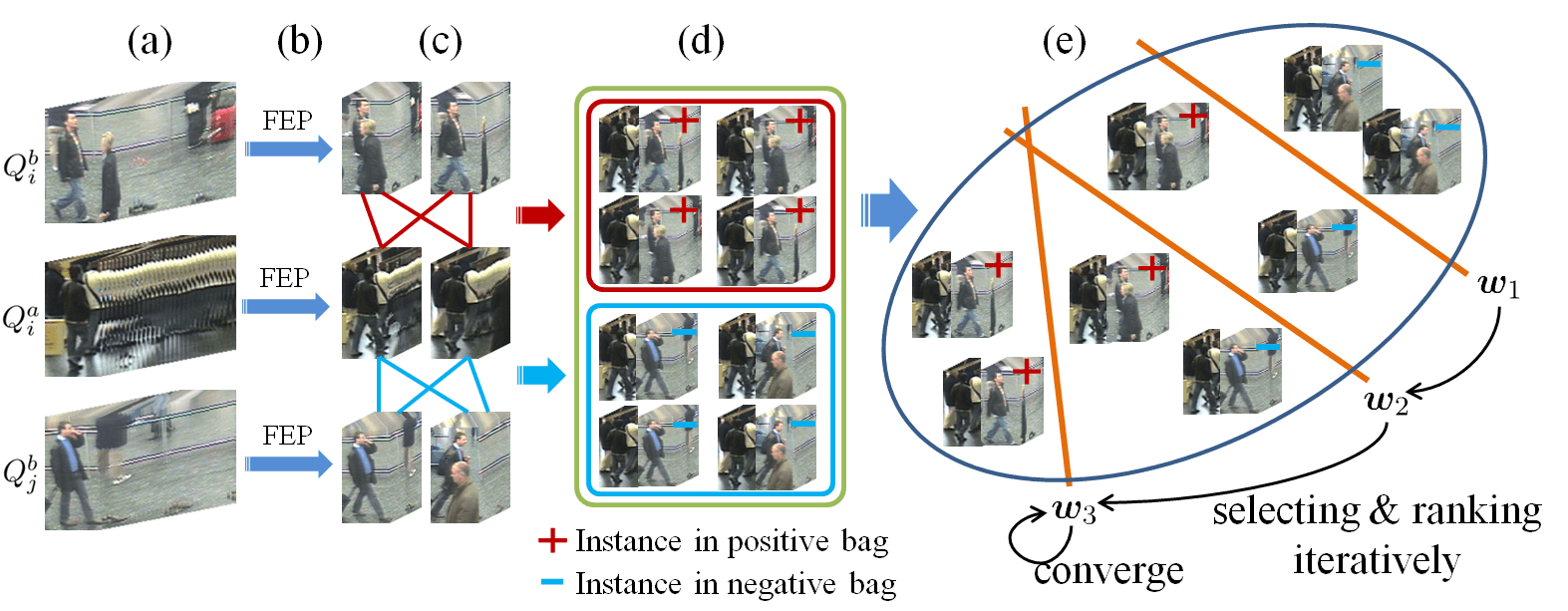
Overview of our approach:
Discriminative Video Ranking (DVR) model learning pipeline:
- Generating candidate fragment pools by Flow Energy Profiling (FEP)
- Creating candidate fragment pairs as positive and negative instances
- Simultaneously selecting and ranking the most discriminative fragment pairs.

Datasets:
Examples of two image sequence based re-id datasets.
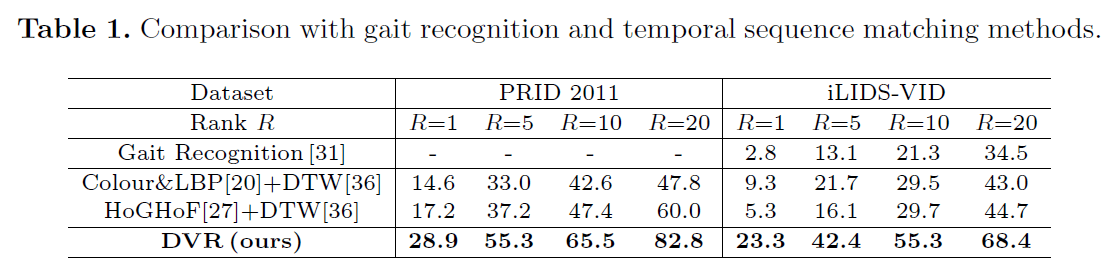
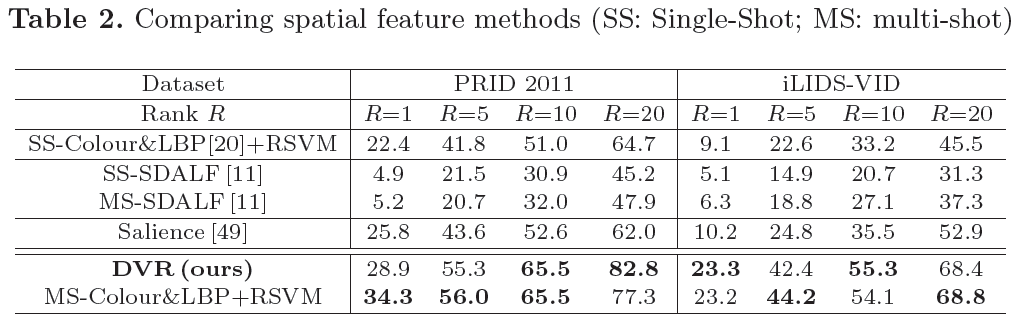
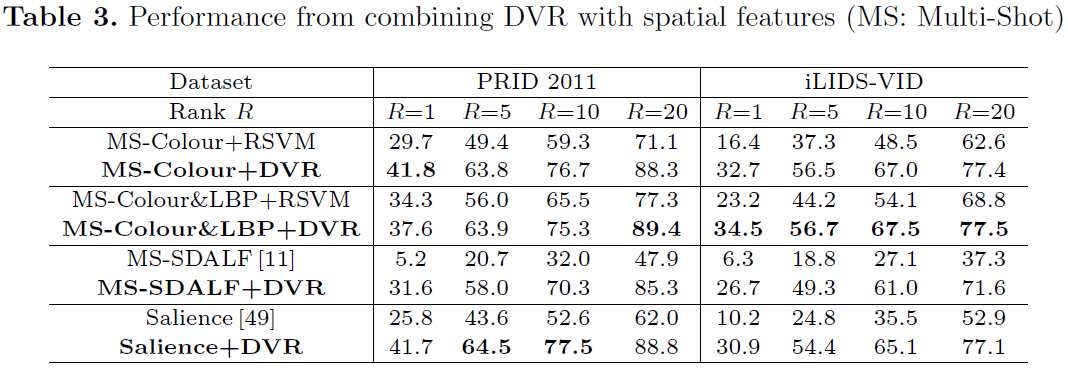
Evaluation:
Comparison of person re-id performance between different methods using Cumulated Matching Characteristics (CMC).
Dataset

An image sequence based person re-identification dataset captured in a crowded public space.
Details ...